
OpenAI Technical Interview Questions 2025 (and How to Answer)
No matter what role you’re applying for at OpenAI, the interview process is intense. As the company behind ChatGPT, GPT-4, and Sora, OpenAI sits at the epicenter of the AI revolution. With over 3,500 employees and $10 billion in revenue, they are scaling rapidly—and they are looking for engineers who can build the future of AGI (Artificial General Intelligence).
Getting a job here is notoriously difficult. The process is fast-paced, highly technical, and deeply focused on mission alignment. Unlike typical “LeetCode-style” interviews, OpenAI emphasizes practical engineering, bug-free code, and safety mindset.
Below, we’ll go through the most common OpenAI interview questions and show you how to answer each one effectively.
Here’s what we’ll cover:
1. Top 5 OpenAI Interview Questions
Based on reports from hundreds of candidates and insights from Glassdoor and Interview Query, these are the 5 foundational questions you must be ready to answer.
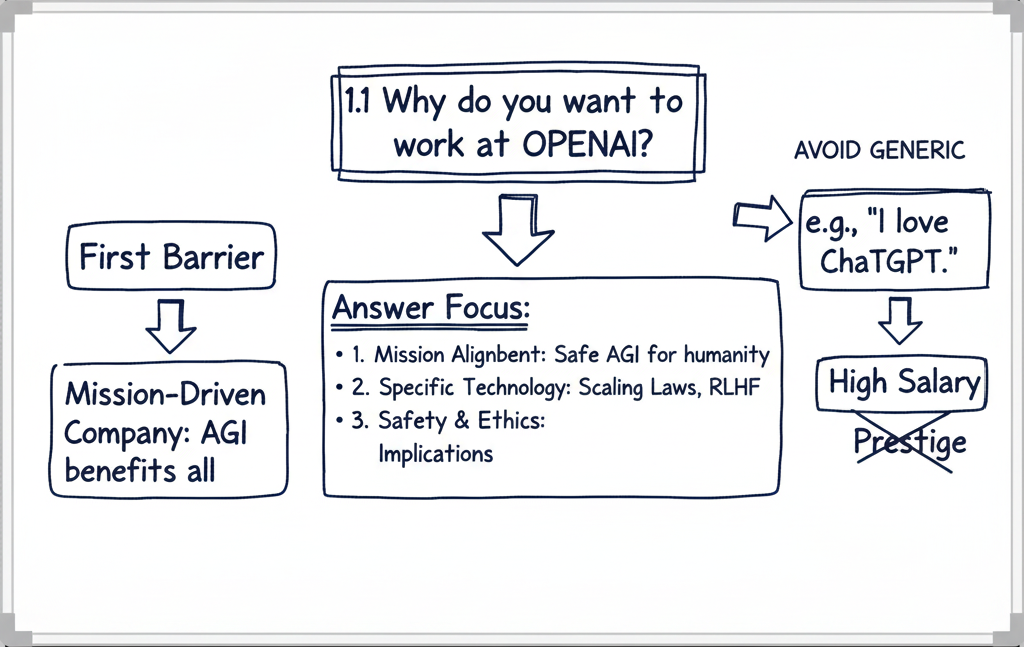
1.1 Why do you want to work at OpenAI?
This is the very first barrier. OpenAI is a mission-driven company dedicated to ensuring AGI benefits all of humanity. Interviewers need to know you are aligned with this specific goal, not just looking for a high salary or prestige.
How to answer this question:
Avoid generic answers like “I love ChatGPT.” Instead, focus on:
- Mission Alignment: Explicitly mention the goal of safe AGI.
- Specific Technology: Discuss specific research papers (e.g., Scaling Laws or RLHF) that excite you.
- Safety & Ethics: Show you care about the implications of what you build.
Example answer:
I’ve followed OpenAI since the release of GPT-2, but what drives me to join now is the company’s unique approach to the ‘alignment problem.’ In my current role, I work on backend scalability, but I want to apply those skills to systems where safety is a primary constraint, not just an afterthought. I was particularly impressed by the rigorous red-teaming process described in the GPT-4 system card. I want to contribute to the Superalignment team’s efforts to build scalable oversight systems, ensuring that as our models get smarter, they remain helpful and harmless.
1.2 Tell me about a time you failed at work
OpenAI moves fast. Mistakes happen. The key indicator of success isn’t perfection; it’s how fast you learn and iterate. This question tests your humility, ownership, and ability to improve systems after a failure.
How to answer this question:
Use the SPSIL framework (Situation, Problem, Solution, Impact, Lessons) to structure your answer clearly.
Example answer:
- Situation: “At my previous startup, I was responsible for deploying a new recommendation engine to production.”
- Problem: “I was so focused on model accuracy that I underestimated the inference latency under high load. When we rolled it out, the P99 latency spiked to 2 seconds, causing timeouts for 15% of users.”
- Solution: “I immediately rolled back the deployment. Then, I profiled the code and realized we were loading heavy feature vectors unnecessarily. I implemented a caching layer and optimized the feature fetch logic.”
- Impact: “We re-deployed two days later. Latency dropped to 200ms, and user engagement increased by 5%.”
- Lessons: “I learned that in production ML systems, latency is a feature. Now, I always include load testing in my CI/CD pipeline before any model hits production, ensuring we catch performance regressions early.”
1.3 What is your favorite AI product? (Product Sense)
Even for engineering roles, OpenAI values “product sense.” They want engineers who understand how users interact with AI. This question tests your ability to critique and appreciate design, utility, and technical implementation.
How to answer this question:
Don’t just pick a product; analyze it. Discuss:
- User Value: What problem does it solve?
- Technical Complexity: What makes it hard to build?
- Improvements: What would you change?
Example answer:
“My favorite recent AI product is actually GitHub Copilot. It solves the ‘blank page’ problem for developers effectively. Technically, I appreciate how it handles context window limitations by intelligently selecting relevant snippets from open tabs, not just the current file. However, if I were improving it, I would focus on ‘project-wide awareness’—allowing the model to index the entire repo dependency graph to understand how a change in one file affects a module defined elsewhere, reducing hallucinated function calls.”
1.4 Implement a SnapshotArray (Practical Coding)
OpenAI’s coding interviews are often described as “practical.” Instead of abstract graph puzzles, you might be asked to implement a data structure or a utility class that mimics real-world needs (like version control or time-travel debugging).
The Question: Implement a SnapshotArray that supports the following operations:
SnapshotArray(length): Initializes an array-like data structure with the given length. Initially, each element equals 0.
set(index, val): Sets the element at the given index to be equal to val.
snap(): Takes a snapshot of the array and returns the snapshot ID: the total number of times we called snap() minus 1.
get(index, snap_id): Returns the value at the given index, at the time we took the snapshot with the given snap_id.
How to answer this question:
- Clarify: Ask about memory constraints. Should we optimize for fast
set, fastsnap, or fastget?
- Naïve Approach: Copy the whole array on every snap. (Too much memory).
- Optimized Approach: Store changes (deltas). Each index can hold a list of versions
[snap_id, value]. Whengetis called, perform a binary search to find the correct value for that snapshot ID.
Example Code (Python):
import bisect
class SnapshotArray:
def __init__(self, length: int):
# List of lists. Each index stores tuples of (snap_id, value)
self.map = [[(0, 0)] for _ in range(length)]
self.snap_id = 0
def set(self, index: int, val: int) -> None:
# If the last entry for this index has the current snap_id, update it
if self.map[index][-1][0] == self.snap_id:
self.map[index][-1] = (self.snap_id, val)
else:
# Otherwise, append a new version
self.map[index].append((self.snap_id, val))
def snap(self) -> int:
self.snap_id += 1
return self.snap_id - 1
def get(self, index: int, snap_id: int) -> int:
history = self.map[index]
# Binary search to find the right version
# We want the rightmost entry with ID <= snap_id
i = bisect.bisect_right(history, (snap_id, float('inf')))
return history[i - 1][1]1.5 Tell me about a time you dealt with conflict
In a high-stakes research environment, engineers and researchers often disagree on priorities (e.g., “Ship this feature now” vs. “Run more safety evals”).
How to answer this question:
Focus on constructive conflict. Show how you used data or principles to resolve the disagreement, rather than personal arguments.
Example answer:
“I was working on a data pipeline where a researcher wanted to remove a filtering step to get more training data, but I was concerned about data quality and potential PII leakage. The conflict stalled progress. I proposed we run a small experiment: we trained two small models, one with the filter and one without. The metrics showed that while the unfiltered model saw more data, it hallucinated significantly more. Seeing the data, the researcher agreed to keep the filter, and we worked together to optimize the filter’s performance instead of removing it.”
2. More OpenAI Interview Questions
We’ve analyzed interview reports to categorize other common questions you might face.
2.1 OpenAI Coding Interview Questions
Coding rounds often focus on correctness and clean code over obscure algorithmic tricks. You are expected to write code that runs.
- Decode String: Given an encoded string, return its decoded string. Solution on LeetCode
- Word Ladder: Find the shortest transformation sequence from a begin word to an end word. Solution on LeetCode
- Design a File System: Create a class to create paths and set values. Solution on LeetCode
- Robot Room Cleaner: Design an algorithm for a robot to clean a room with obstacles. Solution (Premium)
- Game of Life: Implement Conway’s Game of Life (infinite board simulation is a common variation). Solution on LeetCode
- Implement a KV Store: Often with transactional support or time-travel capabilities (similar to SnapshotArray).
2.2 System Design & ML Systems
For Senior and Staff roles, system design is crucial. OpenAI focuses on large-scale distributed systems.
- Design a Web Crawler: How to crawl billions of pages for training data? (Focus on deduplication, politeness, distributed queues).
- Design a Rate Limiter: Critical for API services like the OpenAI API.
- Design a Vector Database: How to store and search billions of embeddings efficiently?
- ML System Design: “Design a system to detect NSFW content in ChatGPT outputs.” Focus on data collection, model selection, latency requirements, and the feedback loop.
2.3 ML & Research Specific Questions
If you are applying for Research Engineer or Member of Technical Staff (MTS) roles, expect questions on the fundamentals of Deep Learning.
- Transformers: Explain the Attention mechanism in detail. What is the complexity of self-attention?
- Training Dynamics: How do you handle vanishing gradients? Explain the difference between Batch Norm and Layer Norm.
- Scaling: How would you train a model that doesn’t fit on a single GPU? (Discuss Data Parallelism vs. Model Parallelism/Sharding).
- Debugging: “Here is a PyTorch script that isn’t converging. Find the bugs.” (Common bugs: forgot
optimizer.zero_grad(), incorrect loss function, untracked tensors).
2.4 Recent Case Studies (2025)
We’ve gathered real interview questions reported by candidates who interviewed at OpenAI in 2025, providing valuable insights into current interview trends.
2.4.1 Case Study 1: Key-Value Store Implementation
Candidates were asked to implement a complete key-value store from scratch with get() and put() operations. The interviewer expected clean code, proper error handling, and discussion of trade-offs (memory vs. speed). Some variations included adding time-based versioning (similar to SnapshotArray) or transactional support.
- Key Focus: Code quality, API design, and ability to discuss scalability considerations
2.4.2 Case Study 2: Enterprise RAG System Design
“Design a system that allows employees to ask questions about internal company documents.” This is a Retrieval-Augmented Generation (RAG) problem. The interviewer was particularly interested in the ML components: choice of embedding models (e.g., OpenAI’s text-embedding-ada-002 vs open-source alternatives), vector database selection (Pinecone, Weaviate, or Chroma), chunking strategies, and retrieval accuracy.
- Key Focus: ML system design, understanding of embeddings, vector search, and how to prevent hallucinations
- Resources: RAG Interview Questions, AWS: What is RAG?, NVIDIA RAG 101
2.4.3 Case Study 3: Toy Language Interpreter (75-minute)
For Research Engineer and ML Engineer candidates, a 75-minute coding session to build a simple interpreter for a toy programming language. The language typically supports variables, basic arithmetic, assignments, and simple control flow (if statements, loops). Candidates must implement lexing, parsing, and execution.
- Key Focus: Compiler theory basics, clean code organization, and ability to build a complete system under time pressure
How to Answer:
Break the problem down into three distinct stages. Explain this structure to your interviewer before you start coding.
- Lexer (Tokenizer): “First, I’ll write a
Lexer. Its job is to take the raw source code string and convert it into a list of tokens. For example,x = 10 + 5;becomes[IDENTIFIER('x'), EQUALS, NUMBER(10), PLUS, NUMBER(5), SEMICOLON].” You can use regular expressions for this.
- Parser: “Next, I’ll build a
Parserthat consumes the token stream from the lexer. I will use a recursive descent approach. It will produce an Abstract Syntax Tree (AST), which is a tree-like data structure that represents the code’s structure. For10 + 5, the AST would be aBinaryOpnode with+as the operator and twoNumberLiteralchildren.”
- Evaluator (Interpreter): “Finally, I’ll write an
Evaluator(or anevalmethod on the AST nodes themselves). This component will recursively ‘walk’ the AST and calculate the result. It needs anEnvironmentobject (a hash map) to store variable states ({'x': 15}). When it encounters aBinaryOpnode, it first evaluates the left and right children, then applies the operator.”
2.4.4 Case Study 4: Probability and Statistical Reasoning
Several candidates reported probability-based puzzles and brain teasers, especially for ML/Research roles. Examples include: calculating conditional probabilities in real-world scenarios (e.g., disease testing), understanding Bayesian inference, expected value calculations, and reasoning about distributions. These questions test whether you can think probabilistically, a critical skill for ML research.
- Key Focus: Probability fundamentals, Bayes’ theorem, conditional probability, and ability to explain reasoning clearly
How to Answer:
When faced with a conditional probability problem, immediately think of Bayes’ Theorem. Talk through your steps clearly.
Step 1: Example Problem:
- A model has a 99% accuracy in detecting spam (true positive rate). However, it has a 2% false positive rate (flags a non-spam email as spam). If only 10% of all emails are actually spam, what is the probability that an email flagged as spam is actually spam?
Step 2: Solution Walkthrough:
- Define Events:
S: The email is Spam.F: The email is Flagged as spam.
- State the Knowns (from the problem):
P(S)= 0.10 (Prior probability of an email being spam)P(not S)= 1 – 0.10 = 0.90P(F|S)= 0.99 (Probability of flagging, given it’s spam – True Positive Rate)P(F|not S)= 0.02 (Probability of flagging, given it’s not spam – False Positive Rate)
- State the Goal:
- We want to find
P(S|F)(Probability it’s spam, given it was flagged).
- We want to find
- Apply Bayes’ Theorem:
P(S|F) = [P(F|S) * P(S)] / P(F)
- Calculate the Denominator, P(F):
- We use the Law of Total Probability. An email can be flagged if it’s spam OR if it’s not spam.
P(F) = P(F|S) * P(S) + P(F|not S) * P(not S)P(F) = (0.99 * 0.10) + (0.02 * 0.90)P(F) = 0.099 + 0.018 = 0.117
- We use the Law of Total Probability. An email can be flagged if it’s spam OR if it’s not spam.
- Calculate the Final Answer:
P(S|F) = (0.99 * 0.10) / 0.117P(S|F) = 0.099 / 0.117 ≈ 0.846
- Final Statement:
- There is an 84.6% chance that an email flagged by this model is actually spam, even though the model is 99% accurate. This shows how a low base rate can significantly affect the real-world performance.
Step 3: Resources:
💡 Key Takeaway: OpenAI interviews in 2025 continue to emphasize practical engineering skills, ML systems understanding, and strong fundamentals. Unlike traditional FAANG interviews, expect less emphasis on obscure algorithms and more focus on building real systems.
3. How to prepare for an OpenAI interview
3.1 Interview Process
The process typically follows these steps:
Step 1: Recruiter Screen:
- High-level fit, interest in OpenAI, and resume walk-through.
Step 2: Technical Screen (1 hour):
- Usually a practical coding problem via CoderPad. You might need to implement a small feature or fix a buggy class. Tip: They often run your code against test cases, so test-driven development helps.
Step 3: Virtual Onsite (4-6 hours):
- Practical Coding: 1-2 rounds.
- System Design: 1 round (Standard or ML-focused).
- Behavioral / Culture Fit: Deep dive into your past projects and alignment with OpenAI’s values.
- Research/ML (Role dependent): Reading a paper and discussing it, or deep-dive ML theory.
3.2 Actionable Preparation Tips
- Read the Papers: Familiarize yourself with GPT-4 Technical Report and InstructGPT.
- Code in Python: It is the standard language of AI. Be comfortable with
numpyand standard libraries.
- Practice “Practical” Problems: Don’t just grind Dynamic Programming. Practice implementing classes, handling edge cases, and writing clean, readable code.
4. OpenAI Interview FAQs
4.1 How hard are OpenAI interviews?
They are considered harder than typical FAANG interviews. While Google or Meta might focus on standard algorithms, OpenAI often presents ambiguous, open-ended engineering problems that require high autonomy. The acceptance rate is extremely low, often cited around 0.5% – 1%.
4.2 Is it all LeetCode?
No. While algorithmic fluency is required, many candidates report “Practical Engineering” rounds where they had to interact with an API, parse a log file, or debug a broken system. The goal is to simulate a real day at work.
4.3 Do I need a PhD?
For Research Scientist roles, a PhD or equivalent track record (published papers in NeurIPS, ICML) is often expected. However, for Research Engineer or Software Engineer roles, a PhD is not required. Strong engineering skills and a solid intuition for ML systems are valued more than academic credentials for these roles.
5. Practice Strategy
5.1 Master the Fundamentals
Before scheduling your interview, ensure you can write a working LRU Cache, Rate Limiter, or Concurrent Queue from scratch in Python without looking up syntax.
5.2 Mock Interviews with Peers
Practice explaining your thought process out loud. OpenAI interviewers look for collaboration. Treat the interviewer as a coworker solving a problem with you.
5.3 Focus on Communication
When you get stuck, don’t stay silent. Say: “I’m thinking of using a Hash Map here to optimize lookup, but the trade-off is memory usage.” This shows engineering maturity.
Ready to prepare? Check out OpenAI’s Research page to get inspired by their latest work.
Good luck!
6. Accelerate Your OpenAI Job Search with Jobright.ai
Landing a role at a pioneering company like OpenAI requires more than just technical skill; it demands a strategic approach to find the right opportunity. While this guide prepares you for the interview, a platform like Jobright.ai gives you a crucial advantage in the job search itself.
6.1 Get Personalized Job Recommendations
Instead of manually sifting through listings, Jobright.ai learns from your profile to deliver tailored recommendations. Whether you’re targeting a Research Engineer, ML Engineer, or Software Engineer role, our platform identifies the best-fit OpenAI opportunities for your background.
6.2 Optimize Your Resume & Gain Team Insights
Our AI analyzes specific OpenAI job descriptions to provide actionable insights on how to optimize your resume, significantly increasing your chances of passing the initial screen. You can also gain intelligence on specific teams, their projects (like GPT-4, DALL-E, Sora, and Superalignment), and their tech stacks, so you can go into interviews fully prepared.
6.3 Start Your Strategic Search Today
Combine the interview preparation strategies in this guide with an intelligent job search platform to maximize your chances of success. Your career at OpenAI starts with finding the right opportunity. Visit Jobright.ai now to start your AI-powered job search, get matched with curated opportunities, and track your progress toward landing your dream offer.